
High-sensitivity pattern discovery in large, paired multi-omic datasets (HAllA) is computational method to find multi-resolution associations in high-dimensional, heterogeneous datasets.
HAllA is an end-to-end statistical method for Hierarchical All-against-All discovery of significant relationships among data features with high power. HAllA is robust to data type, operating both on continuous and categorical values, and works well both on homogeneous datasets (where all measurements are of the same type, e.g. gene expression microarrays) and on heterogeneous data (containing measurements with different units or types, e.g. patient clinical metadata). Finally, it is also aware of multiple input, multiple output problems, in which data might contain of two (or more) distinct subsets sharing an index (e.g. clinical metadata, genotypes, microarrays, and microbiomes all drawn from the same subjects). In all of these cases, HAllA will identify which pairs of features (genes, microbes, loci, etc.) share statistically significant information, without getting tripped up by high-dimensionality.
For more information on the technical aspects:
User Tutorial || Forum || Github
Citation:
Andrew R. Ghazi, Kathleen Sucipto, Ali Rahnavard, Eric A. Franzosa, Lauren J. McIver, Jason Lloyd-Price, Emma Schwager, George Weingart, Yo Sup Moon, Xochitl C. Morgan, Levi Waldron and Curtis Huttenhower, “High-sensitivity pattern discovery in large, paired multi-omic datasets”.
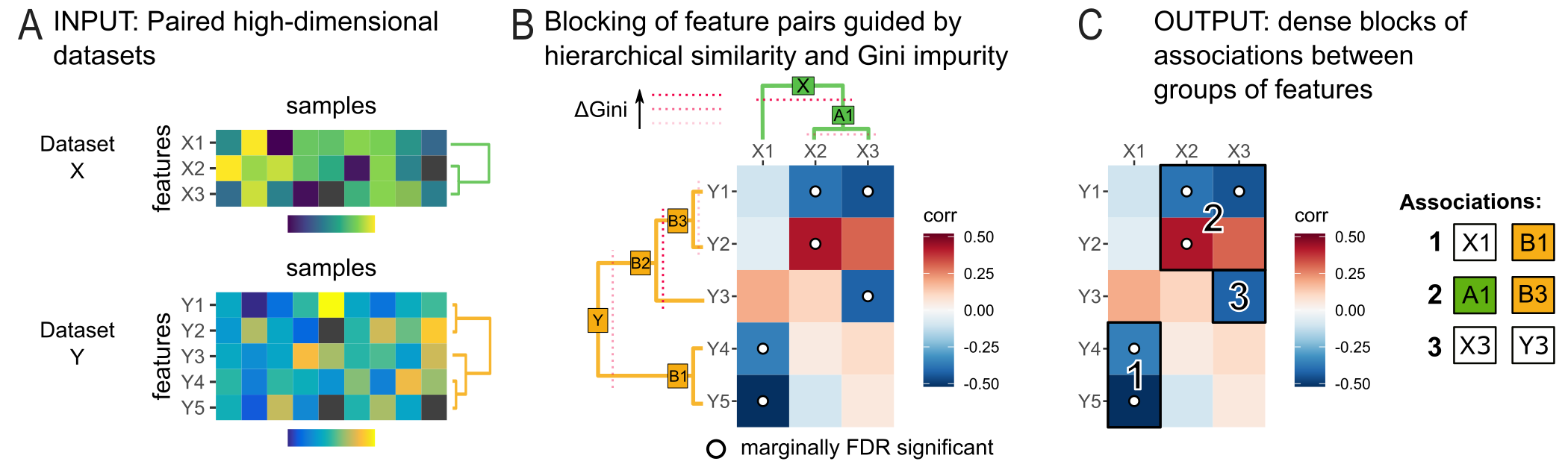
In short, HAllA is like testing for correlation among all pairs of variables in a high-dimensional dataset, but without tripping over multiple hypothesis testing, the problem of figuring out what “relation or association” means for different units or scales, or differentiating between predictor/input or response/output variables.
Its advantages include:
- Generality: HAllA can handle datasets of mixed data types: categorical, binary, or continuous.
- Efficiency: Rather than checking all possible possible associations, HAllA prioritizes computation such that only statistically promising candidate variables are tested in detail.
- Reliability: HAllA utilizes hierarchical false discovery correction to limit false discoveries and loss of statistical power attributed to multiple hypothesis testing.
- Extensibility: HAllA is extensible to use different methods so measurement in its steps.
- Similarity measurement it has the following metrics implemented: normalized mutual information (NMI), Spearman correlation, Pearson correlation, xicor (a.k.a. Chatterjee correlation), and distance correlation (DCOR).
- Dimension reduction - the features in each input dataset are connected by a hierarchical tree according to their similarity. This acts as a simple way of connecting co-varying features into a coherent "block".
- False discovery rate correction (FDR) methods are included: Benjamini–Hochberg–Yekutieli (BHY) as defualt, Benjamini–Hochberg (BH), Bonferroni.
Operating System
* Linux * Mac OS X (>= 10.7.4) * Windows
Software
* Python (>= 3.7) * R (>= 3.6.1) Python packages: * Numpy (>= 1.9.2) * Scipy (>= 0.17.1) * Scikit-learn (>=0.14.1) * matplotlib (>= 1.5.1) * Pandas (>=0.18.1) * jenkspy (>= 0.1.5) * pandas (>= 1.0.5) * PyYAML(>= 5.3.1) * rpy2 (>= 3.3.5) * seaborn (>= 0.10.1) * statsmodels (>= 0.11.1) * tqdm (>= 4.50.2) R packages: * eva (>= 0.2.6) * XICOR (>= 0.3.3)
- Option 1 (Recommended):
pip install halla
Note: Please install the followingR packagesmanually: - Option2: (Install with
setup.py)
git clone https://github.com/biobakery/halla.git
cd halla
python setup.py developOther than Python (version >= 3.7) and R (version >= 3.6.1), install all required libraries listed in requirements.txt, specifically:
Requirements Python packages:
- jenkspy (version >= 0.1.5)
- Matplotlib (version >= 3.5.3)
- NumPy (version >= 1.19.0)
- pandas (version >= 1.0.5)
- PyYAML (version >= 5.4)
- rpy2 (version >= 3.3.5) - Notes on installing
rpy2in macOS - scikit-learn (version >= 0.23.1)
- SciPy (version >= 1.5.1)
- seaborn (version >= 0.10.1)
- statsmodels (version >= 0.11.1)
- tqdm (>=4.50.2)
R packages:
# for MacOS - read the notes on installing rpy2:
# specifically run 'env CC=/usr/local/Cellar/gcc/X.x.x/bin/gcc-X pip install rpy2'
# where X.x.x is the gcc version on the machine **BEFORE** running the following command
conda install -c biobakery hallaType the command:
- General command:
$ halla -X $DATASET1 -Y $DATASET2 --output $OUTPUT_DIR - Example:
$ halla -X X_parabola_F64_S50.txt -Y Y_parabola_F64_S50.txt -o HAllA_OUTPUT
HAllA by default takes two tab-delimited text files as an input, where in each file, each row describes feature (data/metadata) and each column represents an instance. In other words, input X is a D x N matrix where D is the number of dimensions in each instance of the data and N is the number of instances (samples). The “edges” of the matrix should contain labels of the data, if desired.
Note: the input files have the same samples(columns) but features(rows) could be different.
HAllA by default writes the results to “associations.txt”, a tab-delimited text file as output for significant association:
$OUTPUT_DIR = the output directory
$OUTPUT_DIR/associations.txt
- Each row of the assocation.txt tab-delimited file has the following information for each association:
- association_rank: association are sorted for significancy by low pvalues and high similarity score.
- cluster1: has one or more homogenous features from the first dataset that participate in the association.
- cluster1_similarity_score: this value is correspond to `1 – condensed distance` of cluster in the hierarchy of the first dataset.
- cluster2: has one or more homogenous features from the second dataset that participate in the association.
- cluster2_similarity_score: this value is correspond to `1 – condensed distance` of cluster in the hierarchy of the second dataset.
- pvalue : p-value from Benjamini-Hochberg-Yekutieli approach used to assess the statistical significance of the mutual information distance.
- qvalue: q value calculates after BHY correction for each test.
- similarity_score_between_clusters: is the similarity score of the representatives (medoids) of two clusters in the association.
- HAllA provides several plots as complementary outputs including: hallagram for overall plotting results, diagnostics-plot for each association plotting, and heatmaps of original input datasets.